NoSQL 인 Mongo DB 쿼리를 실습해보고자 합니다.
나름 큰 데이터를 사용해볼 것 입니다.
DATA
데이터 내용 : Caselaw Dataset(illinois)로 일리노이주에 있는 재판들을 기록
출처 : https://www.kaggle.com/harvardlil/caselaw-dataset-illinois
Caselaw Dataset (Illinois)
Illinois Caselaw Bulk Data
www.kaggle.com
db.collection이름.stats()를 실행시켜주시면
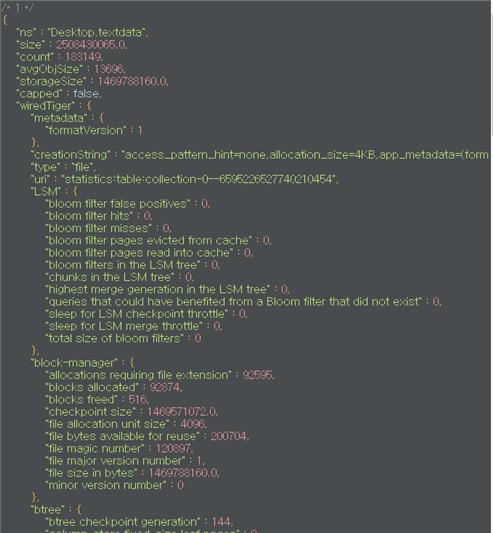
이렇게 나 타는데, 간단하게는 count(row의 수)이고 size는 이 data의 크기입니다.
2GB의 크기고 약 18만 개의 document를 가지고 있습니다.
실습을 시작하기 전에 Document의 구조를 살펴보자면 Document의 구조는 아래와 같은 사진처럼 되어있습니다.

실습 시작
1) 논리연산자와 비교연산자를 섞어서 쿼리를 한번 만들어보겠습니다.
db.textdata.find({"court.name" : "Illinois Supreme Court" , first_page : {$gt:"40"}})
//법원의 이름이 Illinois Supreme Court이고 첫번째 페이지가 40초과 인걸 찾는 쿼리문입니다.
2) regex 연산자와 projection 연산자, AND 연산자( ','로 대체)를 사용해보도록 하겠습니다.
b.textdata.find({decision_date : {$regex : "^20"}},
{_id:0 , decision_date:1, casebody:1})
// 2000년대에 판결난 재판들을 id 필드는 보여주지말고, deision_date와 casebody필드만 보여달라는
// 쿼리문입니다.
// (cf.regex는 ^20 이면 20으로 시작해야한다는 의미입니다.)
3) 이번엔 OR 연산자를 사용해보도록 하겠습니다.
db.textdata.find({$or:[{"jurisdiction": {$ne:"29"}},
{"casebody.opinions.type":"majority"},
{"decsion_date":{$regex:"^2"}},
{"name":{$regex:"^Danny$"}}
]}, {_id:0 , jurisdiction:1, "casebody.data.opinions":1, decsion_date:1,name:1 })
// $or:[{쿼리1}, {쿼리2} .... , {쿼리n}]의 형태로 사용할 수 있습니다.
// embedded document에 대한 접근은 "field이름.field이름" 식으로 '.'을 이용해 접근할 수 있습니다.
// regex에서 ^는 시작이였다면 $는 끝을 의미하고 ^$을 동시에 쓰면 시작, 중간, 끝 다 찾겠다는 의미입니다.
4) 이번엔 find 대신에 aggregate를 사용해 볼 텐데요.
파이프라인 방식으로 동작되며 위에서부터 순차적으로 stage들을 실행하게 됩니다.
db.collection_name.aggregate([{ stage1,stage2,stage3....(생략)}])db.textdata.aggregate([
{$match: {"court.jurisdiction_url" : null}},
{$project : {court :1}}
])
// court라는 embedded docuemnt안에 있는 jurisdiction_url이 null 인 collection을 찾겠다는 의미입니다.
// aggregate에서는 find와는 다르게 $project이라는 연산자를 통해서 projection(어떤 필드를 보여줄지)을 사용합니다.
// $match는 관계형데이터베이스로 치환시켜보면 where의 의미와 유사한데요. 조건을 입력할 수 있습니다.
5) aggregate 또한 $match 안에 논리연산자, 비교연산자 모두 사용 가능합니다!
db.textdata.aggregate([
{$match:
{"court.name" :{$ne : "Illinois Supreme Court"}, "decision_date": {$regex: "^19" },
"volume.volume_number" : {$lt:"2"}}} ])
6) aggregate를 쓰는 가장 큰 이유 중 하나는 $group 연산자인데요. 한 번 사용해보겠습니다.
db.textdata.aggregate([
{$group : {_id : "$reporter.full_name" , count : {$sum:1}}}
{$match : {_id:{$regex : "^Illinois"}}},
{$sort :{ count: -1}}
])
//$group는 관계형데이터베이스에서 group과 같습니다.
// _id: "그룹핑 시킬 필드명"
// count : {$sum:1} 은 $reporter.full_name 로 그룹으로 묶였을 때 각 그룹의 개수를 count: 개수 로 나타내줍니다.
// $sort :{ field1 : 1} -> field1의 필드로 오름차순으로 정렬
// $sort :{ field1 : -1} -> field1의 필드로 내림차순으로 정렬
7) 드디어 마지막!!, 여러 가지를 다 조합해봤는데요.
// Combination of $unwind, $group, $sort and $match
db.textdata.aggregate([
{$unwind : "$casebody.data.attorneys"},
{$group : {_id : "$casebody.data.attorneys" , count : {$sum:1}}},
{$match : {count : {$gt : 50}}},
{$sort : {count : -1}}
])
// $unwind연산자는 field : ["a","b","c"]처럼 배열로 이루어진 구조를 분해시켜줍니다.
// docuemnt1 :[ ~~~~ field : ["a"] ~~~~~~]
// docuemnt2 :[ ~~~~ field : ["b"] ~~~~~~]
// docuemnt3 :[ ~~~~ field : ["c"] ~~~~~~]
// $unwind 연산자를 통해 각 재판을 맡은 변호사목록들을 분해시켰습니다.
// 그리고 $group연산자를 통해 변호사를 기준으로 grouping 시켰고 count를 세봤습니다.
// $match연산자를 통해 변호를 맡은 횟수가 50번 이상만 보이도록 했고
// $sort 연산자를 통해 내림차순으로 정렬시켜보았습니다.
그 결과!

William J.Scott이라는 분이 가장 많은 무려 1031번 재판을 맡은 것을 볼 수 있었는데
어떤 분인가 궁금해서 네이버에 검색을 해보니 변호사와 정치가로 활동하셨다는 것을 볼 수 있었습니다ㅎㅎ

'Mongo DB' 카테고리의 다른 글
| Mogodb Query 실습 (Kaggle 사용)/Wanna Be 컴잘알 (0) | 2019.10.24 |
|---|
